LDA求解之Gibbs采样算法
1. Gibbs采样算法求解LDA的思路
首先,回顾LDA的模型图如下:
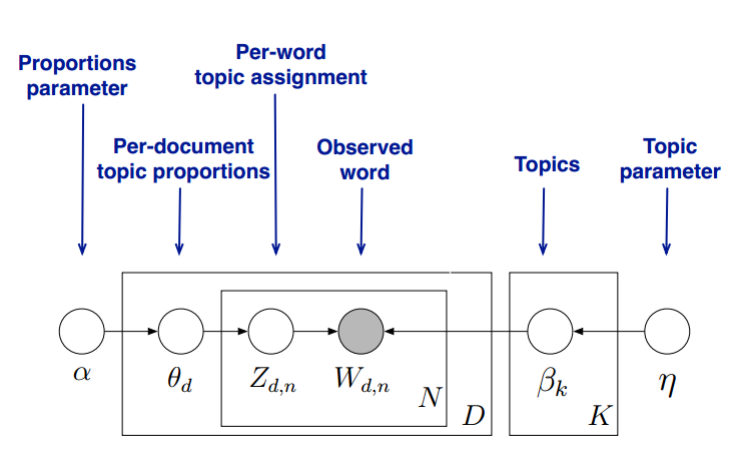
在Gibbs采样算法求解LDA的方法中,我们的$$\alpha, \eta$$是已知的先验输入,我们的目标是得到各个$$z_{dn}, w_{kn}$$对应的整体$$\vec z,\vec w$$的概率分布,即文档主题的分布和主题词的分布。由于我们是采用Gibbs采样法,则对于要求的目标分布,我们需要得到对应分布各个特征维度的条件概率分布。
具体到我们的问题,我们的所有文档联合起来形成的词向量$$\vec w$$是已知的数据,不知道的是语料库主题$$\vec z$$的分布。假如我们可以先求出w,z的联合分布$$p(\vec w,\vec z)$$,进而可以求出某一个词$$w_i$$对应主题特征$$z_i$$的条件概率分布$$p(z_i=k| \vec w,\vec z_{\neg i})$$。其中,$$\vec z_{\neg i}$$代表去掉下标为i的词后的主题分布。有了条件概率分布$$p(z_i=k| \vec w,\vec z_{\neg i})$$,我们就可以进行Gibbs采样,最终在Gibbs采样收敛后得到第i个词的主题。
如果我们通过采样得到了所有词的主题,那么通过统计所有词的主题计数,就可以得到各个主题的词分布。接着统计各个文档对应词的主题计数,就可以得到各个文档的主题分布。
以上就是Gibbs采样算法求解LDA的思路。
2. 主题和词的联合分布与条件分布的求解
从上一节可以发现,要使用Gibbs采样求解LDA,关键是得到条件概率$$p(z_i=k| \vec w,\vec z_{\neg i})$$的表达式。那么这一节我们的目标就是求出这个表达式供Gibbs采样使用。
首先我们简化下Dirichlet分布的表达式,其中$$\triangle(\alpha)$$是归一化参数:$$Dirichlet(\vec p| \vec \alpha) = \frac{\Gamma(\sum\limits_{k=1}K\alpha_k)}{\prod_{k=1}K\Gamma(\alpha_k)}\prod_{k=1}Kp_k{\alpha_k-1} = \frac{1}{\triangle( \vec \alpha)}\prod_{k=1}Kp_k{\alpha_k-1}$$
现在我们先计算下第d个文档的主题的条件分布$$p(\vec z_d|\alpha)$$,在上一篇中我们讲到$$\alpha \to \theta_d \to \vec z_d$$组成了Dirichlet-multi共轭,利用这组分布,计算$$p(\vec z_d| \vec \alpha)$$如下:
$$\begin{aligned} p(\vec z_d| \vec \alpha) & = \int p(\vec z_d | \vec \theta_d) p(\theta_d | \vec \alpha) d \vec \theta_d \ & = \int \prod_{k=1}Kp_k{n_d{(k)}} Dirichlet(\vec \alpha) d \vec \theta_d \ & = \int \prod_{k=1}Kp_k{n_d{(k)}} \frac{1}{\triangle( \vec \alpha)}\prod_{k=1}Kp_k{\alpha_k-1}d \vec \theta_d \ & = \frac{1}{\triangle( \vec \alpha)} \int \prod_{k=1}Kp_k{n_d^{(k)} + \alpha_k-1}d \vec \theta_d \ & = \frac{\triangle(\vec n_d + \vec \alpha)}{\triangle( \vec \alpha)} \end{aligned}$$
其中,在第d个文档中,第k个主题的词的个数表示为:$$n_d{(k)}$$, 对应的多项分布的计数可以表示为$$\vec n_d = (n_d{(1)}, n_d{(2)},...n_d{(K)})$$
有了单一一个文档的主题条件分布,则可以得到所有文档的主题条件分布为:$$p(\vec z|\vec \alpha) = \prod_{d=1}Mp(\vec z_d|\vec \alpha) = \prod_{d=1}M \frac{\triangle(\vec n_d + \vec \alpha)}{\triangle( \vec \alpha)}$$
同样的方法,可以得到,第k个主题对应的词的条件分布$$p(\vec w|\vec z, \vec \eta)$$为:$$p(\vec w|\vec z, \vec \eta) =\prod_{k=1}Kp(\vec w_k|\vec z, \vec \eta) =\prod_{k=1}K \frac{\triangle(\vec n_k + \vec \eta)}{\triangle( \vec \eta)}$$
其中,第k个主题中,第v个词的个数表示为:$$n_k{(v)}$$, 对应的多项分布的计数可以表示为$$\vec n_k = (n_k{(1)}, n_k{(2)},...n_k{(V)})$$
最终我们得到主题和词的联合分布$$p(\vec w, \vec z| \vec \alpha, \vec \eta)$$如下:$$p(\vec w, \vec z) \propto p(\vec w, \vec z| \vec \alpha, \vec \eta) = p(\vec z|\vec \alpha) p(\vec w|\vec z, \vec \eta) = \prod_{d=1}M \frac{\triangle(\vec n_d + \vec \alpha)}{\triangle( \vec \alpha)}\prod_{k=1}K \frac{\triangle(\vec n_k + \vec \eta)}{\triangle( \vec \eta)}$$
有了联合分布,现在我们就可以求Gibbs采样需要的条件分布$$p(z_i=k| \vec w,\vec z_{\neg i})$$了。需要注意的是这里的i是一个二维下标,对应第d篇文档的第n个词。
对于下标i,由于它对应的词$$w_i$$是可以观察到的,因此我们有:$$p(z_i=k| \vec w,\vec z_{\neg i}) \propto p(z_i=k, w_i =t| \vec w_{\neg i},\vec z_{\neg i})$$
对于$$z_i=k, w_i =t$$,它只涉及到第d篇文档和第k个主题两个Dirichlet-multi共轭,即:
$$\vec \alpha \to \vec \theta_d \to \vec z_d$$
$$\vec \eta \to \vec \beta_k \to \vec w_{(k)}$$
其余的M+K-2个Dirichlet-multi共轭和它们这两个共轭是独立的。如果我们在语料库中去掉$$z_i,w_i,$$并不会改变之前的M+K个Dirichlet-multi共轭结构,只是向量的某些位置的计数会减少,因此对于$$\vec \theta_d, \vec \beta_k$$,对应的后验分布为:$$p(\vec \theta_d | \vec w_{\neg i},\vec z_{\neg i}) = Dirichlet(\vec \theta_d | \vec n_{d, \neg i} + \vec \alpha)$$
$$p(\vec \beta_k | \vec w_{\neg i},\vec z_{\neg i}) = Dirichlet(\vec \beta_k | \vec n_{k, \neg i} + \vec \eta)$$
现在开始计算Gibbs采样需要的条件概率:
$$\begin{aligned} p(z_i=k| \vec w,\vec z_{\neg i}) & \propto p(z_i=k, w_i =t| \vec w_{\neg i},\vec z_{\neg i}) \ & = \int p(z_i=k, w_i =t, \vec \theta_d , \vec \beta_k| \vec w_{\neg i},\vec z_{\neg i}) d\vec \theta_d d\vec \beta_k \ & = \int p(z_i=k, \vec \theta_d | \vec w_{\neg i},\vec z_{\neg i})p(w_i=t, \vec \beta_k | \vec w_{\neg i},\vec z_{\neg i}) d\vec \theta_d d\vec \beta_k \ & = \int p(z_i=k|\vec \theta_d )p( \vec \theta_d | \vec w_{\neg i},\vec z_{\neg i})p(w_i=t|\vec \beta_k)p(\vec \beta_k | \vec w_{\neg i},\vec z_{\neg i}) d\vec \theta_d d\vec \beta_k \ & = \int p(z_i=k|\vec \theta_d ) Dirichlet(\vec \theta_d | \vec n_{d, \neg i} + \vec \alpha) d\vec \theta_d \ & * \int p(w_i=t|\vec \beta_k) Dirichlet(\vec \beta_k | \vec n_{k, \neg i} + \vec \eta) d\vec \beta_k \ & = \int \theta_{dk} Dirichlet(\vec \theta_d | \vec n_{d, \neg i} + \vec \alpha) d\vec \theta_d \int \beta_{kt} Dirichlet(\vec \beta_k | \vec n_{k, \neg i} + \vec \eta) d\vec \beta_k \ & = E_{Dirichlet(\theta_d)}(\theta_{dk})E_{Dirichlet(\beta_k)}(\beta_{kt})\end{aligned}$$
在上一篇LDA基础里我们讲到了Dirichlet分布的期望公式,因此我们有:
$$E_{Dirichlet(\theta_d)}(\theta_{dk}) = \frac{n_{d, \neg i}{k} + \alpha_k}{\sum\limits_{s=1}Kn_{d, \neg i}^{s} + \alpha_s}$$
$$E_{Dirichlet(\beta_k)}(\beta_{kt})= \frac{n_{k, \neg i}{t} + \eta_t}{\sum\limits_{f=1}Vn_{k, \neg i}^{f} + \eta_f}$$
最终我们得到每个词对应主题的Gibbs采样的条件概率公式为:
$$p(z_i=k| \vec w,\vec z_{\neg i}) = \frac{n_{d, \neg i}{k} + \alpha_k}{\sum\limits_{s=1}Kn_{d, \neg i}{s} + \alpha_s} \frac{n_{k, \neg i}{t} + \eta_t}{\sum\limits_{f=1}Vn_{k, \neg i}{f} + \eta_f}$$
有了这个公式,我们就可以用Gibbs采样去采样所有词的主题,当Gibbs采样收敛后,即得到所有词的采样主题。
利用所有采样得到的词和主题的对应关系,我们就可以得到每个文档词主题的分布$$\theta_d$$和每个主题中所有词的分布$$\beta_k$$。
3. LDA Gibbs采样算法流程总结
现在我们总结下LDA Gibbs采样算法流程。首先是训练流程:
1) 选择合适的主题数K, 选择合适的超参数向量$$\vec \alpha,\vec \eta$$
2) 对应语料库中每一篇文档的每一个词,随机的赋予一个主题编号z
3) 重新扫描语料库,对于每一个词,利用Gibbs采样公式更新它的topic编号,并更新语料库中该词的编号。
4) 重复第2步的基于坐标轴轮换的Gibbs采样,直到Gibbs采样收敛。
5) 统计语料库中的各个文档各个词的主题,得到文档主题分布$$\theta_d$$,统计语料库中各个主题词的分布,得到LDA的主题与词的分布$$\beta_k$$。
下面我们再来看看当新文档出现时,如何统计该文档的主题。此时我们的模型已定,也就是LDA的各个主题的词分布$$\beta_k$$已经确定,我们需要得到的是该文档的主题分布。因此在Gibbs采样时,我们的$$E_{Dirichlet(\beta_k)}(\beta_{kt})$$已经固定,只需要对前半部分$$E_{Dirichlet(\theta_d)}(\theta_{dk})$$进行采样计算即可。
现在我们总结下LDA Gibbs采样算法的预测流程:
1) 对应当前文档的每一个词,随机的赋予一个主题编号z
2) 重新扫描当前文档,对于每一个词,利用Gibbs采样公式更新它的topic编号。
3) 重复第2步的基于坐标轴轮换的Gibbs采样,直到Gibbs采样收敛。
4) 统计文档中各个词的主题,得到该文档主题分布。
4. LDA Gibbs采样算法小结
使用Gibbs采样算法训练LDA模型,我们需要先确定三个超参数K, $$\vec \alpha,\vec \eta$$。其中选择一个合适的K尤其关键,这个值一般和我们解决问题的目的有关。如果只是简单的语义区分,则较小的K即可,如果是复杂的语义区分,则K需要较大,而且还需要足够的语料。
由于Gibbs采样可以很容易的并行化,因此也可以很方便的使用大数据平台来分布式的训练海量文档的LDA模型。以上就是LDA Gibbs采样算法。