感知机
感知机(Peceptron)是二类分类的线性分类模型,其输入为实例的特征向量,输出为实例的类别,取$$+1$$和$$-1$$二值。感知机将对应于输入空间(特征空间)中将实例划分为正负的分离超平面,属于判别模型。
1. 定义
假设输入空间(特征空间)是$$X \subseteq R^n$$,输出空间是$$Y=\lbrace+1,-1\rbrace$$。输入$$x\in X$$表示实例的特征向量,对应于输入空间(特征空间)的点;输出$$y\in Y$$表示实例的类别。由输入空间到输出空间的如下函数:
$$ f(x)=sign(w\cdot x+b) $$
称为感知机。其中,$$w$$和$$b$$为感知模型参数,$$w\in R^n$$叫做权值(weight)或权值向量(weight vector),$$b\in R$$叫做偏置,$$w\cdot x$$表示向量$$w$$和向量$$x$$的内积。$$sign$$是符号函数,即
$$ sign(x) = \begin{cases} +1 &\text{if } x>=0 \ -1 &\text{if } x<0 \end{cases} $$
感知机是一种线性分类模型,属于判别模型。
感知模型的假设空间是定义在特征空间中的所有线性分类模型(linear classification model)或线性分类器(linear classifier),即函数集合$${f\vert f(x)=w\cdot x+b}$$。
2.几何解释
线性方程$$w\cdot x+b=0$$对应于特征空间$$R^n$$中的一个超平面$$S$$,其中$$w$$是超平面的法向量,$$b$$是超平面的截距。这个超平面将特征空间划分为两部分。位于两部分的点(特征向量)分别被分为正负两类,因此,超平面$$S$$称为分离超平面(separating hyperplane),如图所示。
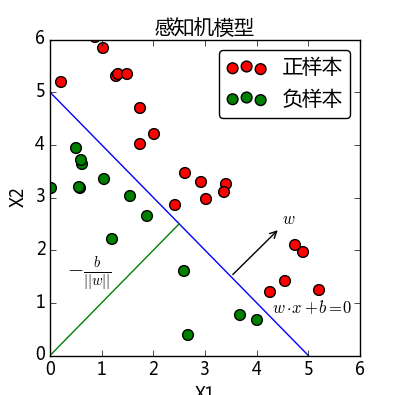
其中超平面上的任意两个向量,比如为$$x{(i)}$$,$$x{(j)}$$满足方程(这里用上标表示不同的向量,下标用来表示向量中的分量,跟原书不同)
$$w\cdot x^{(i)} = -b$$
$$w\cdot x^{(j)} = -b$$
则$$w\cdot (x{(i)}-x{(j)})=0$$,也就是超平面上任意两个向量相减构成的向量与$$w$$的内积为$$0$$,则互相垂直。对于超平面来讲$$w$$的方向并不重要,只需要垂直于超平面即可。
满足$$w\cdot x+b>0$$的的向量$$x $$位于超平面跟$$w$$的方向一致的一面,满足$$w\cdot x+b<0$$的向量$$x$$位于超平面跟$$w$$方向相反的一面。因为取超平面上任意一个向量假设为$$x{(1)}$$,则超平面外的任何一向量$$x{(0)}$$满足$$w\cdot (x{(0)}-x{(1)})>0$$,则说明这两向量相减构成的向量跟$$w$$的夹角小于90度,反之小于0,则夹角大于90度。
超平面外的任意一个点$$x^{(0)}$$到超平面$$S$$的距离为
$$ \dfrac{|w\cdot x^{(0)}+b|}{||w||} $$
其中$$||w||$$是$$w$$的$$L_2$$范数,也就是欧式距离$$||w||=\sqrt{w_12 +w_22+...+w_n^2}$$.
3. 感知机的学习策略
为了确定感知机模型参数$$w$$和$$b$$,需要确定一个学习策略,即定义(经验 )损失函数并将损失函数最小化。
损失函数的一个自然选择是误分类点的总数,但是这样的损失函数不是参数$$w$$和$$b$$的连续可导函数,不易优化。另外一种选择是所有误分类点到超平面的总距离。其次,对于误分类点的数据$$(x{(i)},y{(i)})$$来说,满足$$-y{(i)}(w\cdot x{(i)}+b)>0$$,因为当$$w\cdot x{(i)}+b>0$$时,$$y{(i)} = -1$$,而当$$-y{(i)}(w\cdot x{(i)}+b)<0$$时,$$y{(i)} = 1$$。因此误分类点$$x{(i)}$$到超平面$$S$$的距离是
$$ -y{(i)} \dfrac{w\cdot x{(i)}+b}{||w||} $$
这样,假设所有超平面$$S$$的误分类点结合为$$M$$,那么所有误分类点到超平面$$S$$的总距离为
$$ -\dfrac{1}{||w||}\displaystyle\sum_{x{(i)}\in M}y{(i)}(w\cdot x^{(i)}i+b) $$
不考虑$$\dfrac{1}{||w||}$$,则我们得到感知机的损失函数:$$-\displaystyle\sum_{x{(i)}\in M}y{(i)}(w\cdot x^{(i)}+b)$$。(这里个人理解为任意一个超平面的法向量$$w$$都可以经过缩放成为单位向量)
给定训练数据集合$$T={(x{(1)},y{(1)}),(x{(2)},y{(2)}),...,(x{(m)},y{(m)})}$$,其中$$x{(i)}\in X= Rn$$,$$y^{(i)}\in Y=\lbrace+1,-1\rbrace$$,$$i=1,2,...,m$$。感知学习机$$sign(w\cdot x+b)$$的损失函数定义为
$$ L(w,b)=-\displaystyle\sum_{x{(i)}\in M}y{(i)}(w\cdot x^{(i)}+b) $$
这个损失函数就是感知学习机的经验风险函数。它是$$w$$,$$b$$的连续可导函数。显然它是非负函数。如果没有误分类点,则损失函数为0,而且误分类点越少,误分类点离超平面越近,损失函数越小。
参考文献:
统计学习方法,李航
http://blog.csdn.net/wangxin1982314/article/details/73529499