#难以想象的for
看这个标题,有点匪夷所思吗?为什么for是难以想象的呢?因为在python中,它的确是很常用而且很强悍,强悍到以至于另外一个被称之为迭代的东西,在python中就有点相形见绌了。在别的语言中,for的地位从来没有如同python中这么高的。
废话少说,上干活。
##for的基本操作
for是用来循环的,是从某个对象那里依次将元素读取出来。看下面的例子,将已经学习过的数据对象用for循环一下,看看哪些能够使用,哪些不能使用。同时也是复习一下过往的内容。
>>> name_str = "qiwsir"
>>> for i in name_str: #可以对str使用for循环
... print i,
...
q i w s i r
>>> name_list = list(name_str)
>>> name_list
['q', 'i', 'w', 's', 'i', 'r']
>>> for i in name_list: #对list也能用
... print i,
...
q i w s i r
>>> name_set = set(name_str) #set还可以用
>>> name_set
set(['q', 'i', 's', 'r', 'w'])
>>> for i in name_set:
... print i,
...
q i s r w
>>> name_tuple = tuple(name_str)
>>> name_tuple
('q', 'i', 'w', 's', 'i', 'r')
>>> for i in name_tuple: #tuple也能呀
... print i,
...
q i w s i r
>>> name_dict={"name":"qiwsir","lang":"python","website":"qiwsir.github.io"}
>>> for i in name_dict: #dict也不例外
... print i,"-->",name_dict[i]
...
lang --> python
website --> qiwsir.github.io
name --> qiwsir
除了上面的数据类型之外,对文件也能够用for,这在前面有专门的《不要红头文件》两篇文章讲解有关如何用for来读取文件对象的内容。看官若忘记了,可去浏览。
for在list解析中,用途也不可小觑,这在讲解list解析的时候,也已说明,不过,还是再复习一下为好,所谓学而时常复习之,不亦哈哈乎。
>>> one = range(1,9)
>>> one
[1, 2, 3, 4, 5, 6, 7, 8]
>>> [ x for x in one if x%2==0 ]
[2, 4, 6, 8]
什么也不说了,list解析的强悍,在以后的学习中会越来越体会到的,佩服佩服呀。
列位如果用python3,会发现字典解析、元组解析也是奇妙的呀。
要上升一个档次,就得进行概括。将上面所说的for循环,概括一下,就是下图所示:
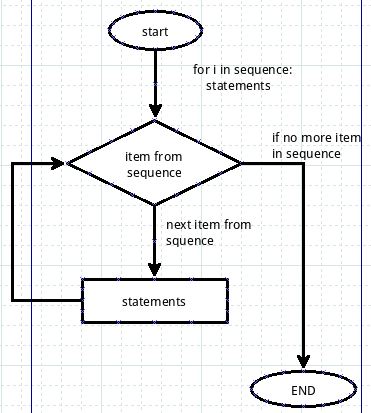
用一个文字表述:
for iterating_var in sequence:
statements
iterating_var是对象sequence的迭代变量,也就是sequence必须是一个能够有某种序列的对象,特别注意没某种序列,就是说能够按照一定的脚标获取元素。当然,文件对象属于序列,我们没有用脚标去获取每行,如果把它读取出来,因为也是一个str,所以依然可以用脚标读取其内容。
##zip
zip是什么东西?在交互模式下用help(zip),得到官方文档是:
zip(...) zip(seq1 [, seq2 [...]]) -> [(seq1[0], seq2[0] ...), (...)]
Return a list of tuples, where each tuple contains the i-th element from each of the argument sequences. The returned list is truncated in length to the length of the shortest argument sequence.
通过实验来理解上面的文档:
>>> a = "qiwsir"
>>> b = "github"
>>> zip(a,b)
[('q', 'g'), ('i', 'i'), ('w', 't'), ('s', 'h'), ('i', 'u'), ('r', 'b')]
>>> c = [1,2,3]
>>> d = [9,8,7,6]
>>> zip(c,d)
[(1, 9), (2, 8), (3, 7)]
>>> e = (1,2,3)
>>> f = (9,8)
>>> zip(e,f)
[(1, 9), (2, 8)]
>>> m = {"name","lang"}
>>> n = {"qiwsir","python"}
>>> zip(m,n)
[('lang', 'python'), ('name', 'qiwsir')]
>>> s = {"name":"qiwsir"}
>>> t = {"lang":"python"}
>>> zip(s,t)
[('name', 'lang')]
zip是一个内置函数,它的参数必须是某种序列数据类型,如果是字典,那么键视为序列。然后将序列对应的元素依次组成元组,做为一个list的元素。
下面是比较特殊的情况,参数是一个序列数据的时候,生成的结果样子:
>>> a
'qiwsir'
>>> c
[1, 2, 3]
>>> zip(c)
[(1,), (2,), (3,)]
>>> zip(a)
[('q',), ('i',), ('w',), ('s',), ('i',), ('r',)]
这个函数和for连用,就是实现了:
>>> c
[1, 2, 3]
>>> d
[9, 8, 7, 6]
>>> for x,y in zip(c,d): #实现一对一对地打印
... print x,y
...
1 9
2 8
3 7
>>> for x,y in zip(c,d): #把两个list中的对应量上下相加。
... print x+y
...
10
10
10
上面这个相加的功能,如果不用zip,还可以这么写:
>>> length = len(c) if len(c)<len(d) else len(d) #判断c,d的长度,将短的长度拿出来
>>> for i in range(length):
... print c[i]+d[i]
...
10
10
10
以上两种写法那个更好呢?前者?后者?哈哈。我看差不多了。还可以这么做呢:
>>> [ x+y for x,y in zip(c,d) ]
[10, 10, 10]
前面多次说了,list解析强悍呀。当然,还可以这样的:
>>> [ c[i]+d[i] for i in range(length) ]
[10, 10, 10]
for循环语句在后面还会经常用到,其实前面已经用了很多了。所以,看官应该不感到太陌生。