爬虫学习使用指南
Auth: 王海飞
Data:2018-07-05
Email:779598160@qq.com
github:https://github.com/coco369/knowledge
前言
说到分布式系统的时候,要和集中式系统进行对比的学习,下面就先介绍下集中式系统,对比它们的优缺点进行学习。
集中式系统
集中式系统:
集中式系统中整个项目就是一个独立的应用,整个应用也就是整个项目,所有的业务逻辑功能都在一个应用里面。如果遇到并发的瓶颈的时候,就多增加几台服务器来部署项目,以此来解决并发分问题。在nginx中进行负载均衡即可。
缺点:
a) 不易于扩展
b) 如果发现你的项目代码中有bug的话,那么你的所有的服务器中的项目代码都是有问题的,这时候要更新这个bug的时候,就需要同时更新所有的服务器了。
优点:
维护方便
分布式系统
分布式系统:
分布式系统中,我们的整个项目可以拆分成很多业务块,每一个业务块单独进行集群的部署。这样就将整个项目分开了,在进行拓展的时候,系统是很容易横向拓展的。在并发的时候,也很好的将用户的并发量提上去。
缺点:
a) 项目拆分的过于复杂,给运维带来了很高的维护成本
b) 数据的一致性,分布式事务,分布式锁等问题不能得到很好的解决
优点:
a) 一个业务模块崩了,并不影响其他的业务
b) 利于扩展
c) 在上线某个新功能的时候,只需要新增对应的分布式的节点即可,测试也只需要测试该业务功能即可。很好的避免了测试在上线之前需要将整个系统进行全方面的测试
1. scrapy的分布式原理
我们还是先回顾下scrapy的运行原理的构造图:
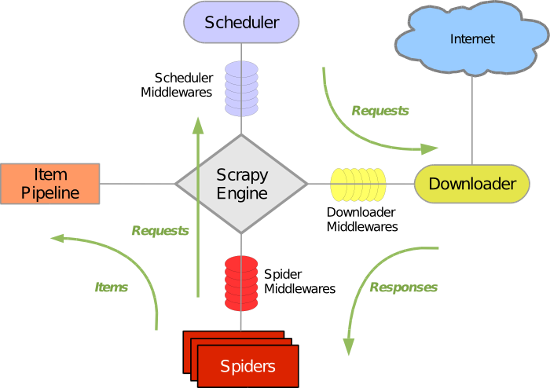
该图很好的阐释了在不是scrapy的服务器中的运行结构图,在维护爬取的url队列的时候,使用scheduler进行调度的。那么如果要修改为分布式的scrapy爬虫的话,其实就是将爬取的队列进行共享,多台部署了scrapy爬虫的服务器共享该爬取队列。
2. 分布式架构:
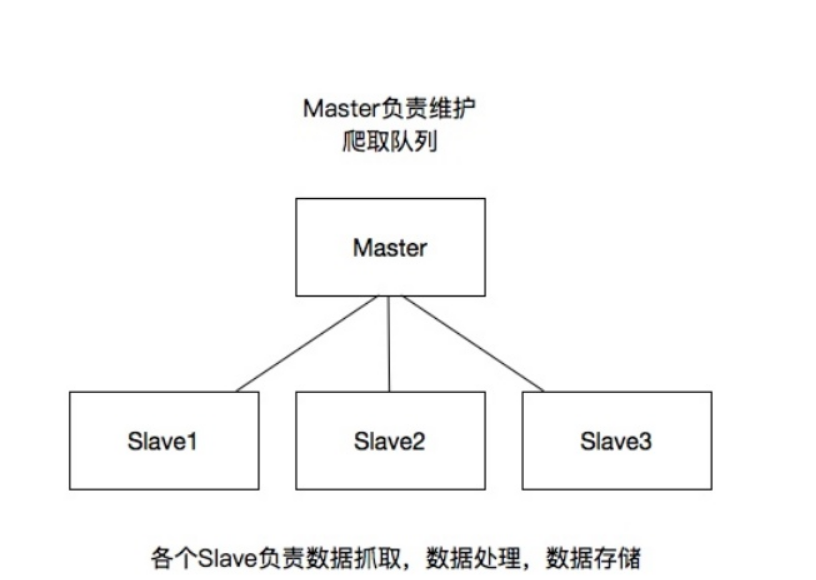
master-主机:维护爬虫队列。
slave-从机:数据爬取,数据处理,数据存储。
3. 搭建分布式爬虫
我们使用scrapy_redis进行分布式爬虫的搭建。
scrapy_redis是scrapy框架下的一个插件,通过重构调度器来使我们的爬虫运行的更快
3.1 安装
安装scrapy_redis:
pip install scrapy_redis
安装redis:
# redis可以仅在master主机上安装
pip install redis
安装数据存储数据库,采用mongodb 见: 安装配置地址
3.2 redis
在维护爬虫队列的时候,很多爬虫项目同时读取队列中的信息,就造成了可能读数据重复了,比如同时读取同一个url。为了避免这种情况,我们建议使用redis去维护队列。而且redis的集合中的元素还不是重复的,可以很好的利用这一点,进行url爬取地址的存储
3.3 分布式爬虫改造
3.3.1 master
master主机改造: 在master主机上安装redis并启动,最好设置密码
spiders文件中定义的爬虫py文件修改如下:
如下爬虫实现的功能是拿到需要爬取的成都各大区县的二手房页面url地址,包括分页的地址。并将数据存储到redis中
import json
from scrapy import Request
from scrapy.spiders import Spider
from scrapy.selector import Selector
from lianjiaspider.items import LianjiaspiderItem, MasterItem
class LianJiaSpider(Spider):
name = 'lianjia'
# allowed_domains = ['lianjia.com']
domains_url = 'https://cd.lianjia.com'
start_linjia_url = 'https://cd.lianjia.com/ershoufang'
def start_requests(self):
yield Request(self.start_linjia_url)
def parse(self, response):
sel = Selector(response)
ershoufang_aera = sel.xpath('//div[@data-role="ershoufang"]')
area_info = ershoufang_aera.xpath('./div/a')
for area in area_info:
area_href = area.xpath('./@href').extract()[0]
area_name = area.xpath('./text()').extract()[0]
yield Request(self.domains_url + area_href,
callback=self.parse_house_info,
meta={'name': area_name, 'href': area_href})
def parse_house_info(self, response):
sel = Selector(response)
page_box = sel.xpath('//div[@class="page-box house-lst-page-box"]/@page-data').extract()
total_page = json.loads(page_box[0]).get('totalPage')
for i in range(1, int(total_page)+1):
item = MasterItem()
item['url'] = self.domains_url + response.meta.get('href') + 'pg' + str(i)
yield item
定义Item
接收一个地址url参数:
class MasterItem(scrapy.Item):
url = scrapy.Field()
新增redis存储中间件
class MasterPipeline(object):
def __init__(self):
# 链接redis
self.r = redis.Redis(host='127.0.0.1', port=6379)
def process_item(self, item, spider):
# 向redis中插入需要爬取的链接地址
self.r.lpush('lianjia:start_urls', item['url'])
3.3.2 slave改造:
slave从机改造:slave从机访问redis,直接去访问master主机上的redis的地址,以及端口密码等信息
spiders爬虫文件改造
继承改为继承Redisspider
from scrapy_redis.spiders import RedisSpider
具体代码优化如下:
from scrapy_redis.spiders import RedisSpider
from scrapy.selector import Selector
from lianjiaspider.items import LianjiaspiderItem
class LianJiaSpider(RedisSpider):
name = 'lianjia'
# 指定访问redis的爬取urls的队列
redis_key = 'lianjia:start_urls'
def parse(self, response):
sel = Selector(response)
lis = sel.xpath('//html/body/div[4]/div[1]/ul/li[@class="clear"]')
for li in lis:
item = LianjiaspiderItem()
item['house_code'] = li.xpath('./a/@data-housecode').extract()[0]
if li.xpath('./a/img/@src').extract():
item['img_src'] = li.xpath('./a/img/@src').extract()[0]
if li.xpath('./div/div/a/text()').extract():
item['title'] = li.xpath('./div/div/a/text()').extract()[0]
item['address'] = li.xpath('./div/div[2]/div/a/text()').extract()
item['info'] = li.xpath('./div/div[2]/div/text()').extract()
item['flood'] = li.xpath('./div/div[3]/div/text()').extract()
item['tag'] = li.xpath('.//div[@class="tag"]/span/text()').extract()
item['type'] = 'ershoufang'
item['city'] = '成都'
yield item
def split_house_info(self, info):
return [i.strip() for i in info.split('|')[1:]]
settings.py配置改造
新增如下的配置:
# scrapy-redis
REDIS_URL = 'redis://:yzd@127.0.0.1:6379' # for master
# REDIS_URL = 'redis://:yzd@10.140.0.2:6379' # for slave (master's ip)
# SCHEDULER 是任务分发与调度,把所有的爬虫开始的请求都放在redis里面,所有爬虫都去redis里面读取请求。
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
# 如果这一项设为True,那么在Redis中的URL队列不会被清理掉,但是在分布式爬虫共享URL时,要防止重复爬取。如果设为False,那么每一次读取URL后都会将其删掉,但弊端是爬虫暂停后重新启动,他会重新开始爬取。
SCHEDULER_PERSIST = True
# REDIS_START_URLS_AS_SET指的是使用redis里面的set类型(简单完成去重),如果你没有设置,默认会选用list。
REDIS_START_URLS_AS_SET = True
# DUPEFILTER_CLASS 是去重队列,负责所有请求的去重
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
# 爬虫的请求调度算法,有三种可供选择
# scrapy_redis.queue.SpiderQueue:队列。先入先出队列,先放入Redis的请求优先爬取;
# scrapy_redis.queue.SpiderStack:栈。后放入Redis的请求会优先爬取;
# scrapy_redis.queue.SpiderPriorityQueue:优先级队列。根据优先级算法计算哪个先爬哪个后爬
SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderQueue"
# 设置链接redis的配置,或者如下分别设置端口和IP地址
REDIS_URL = 'redis://127.0.0.1:6379'
# 分布式爬虫设置Ip端口
REDIS_HOST = '127.0.0.1'
REDIS_PORT = 6379