目录 start
目录 end |2018-06-21| 码云 | CSDN | OSChina
Java基础
【类和字节码】
类加载和类对象
- 一个
.class文件定义了JVM中的类型,包括了域,方法,继承信息,注解和其他元数据
类加载器
- TODO 学习类加载器
[类装载器、双亲委托模型、命名空间、安全性](https://blog.csdn.net/yuan22003/article/details/6839335) java ClassLoader类解析-双亲委托机制
加载和连接
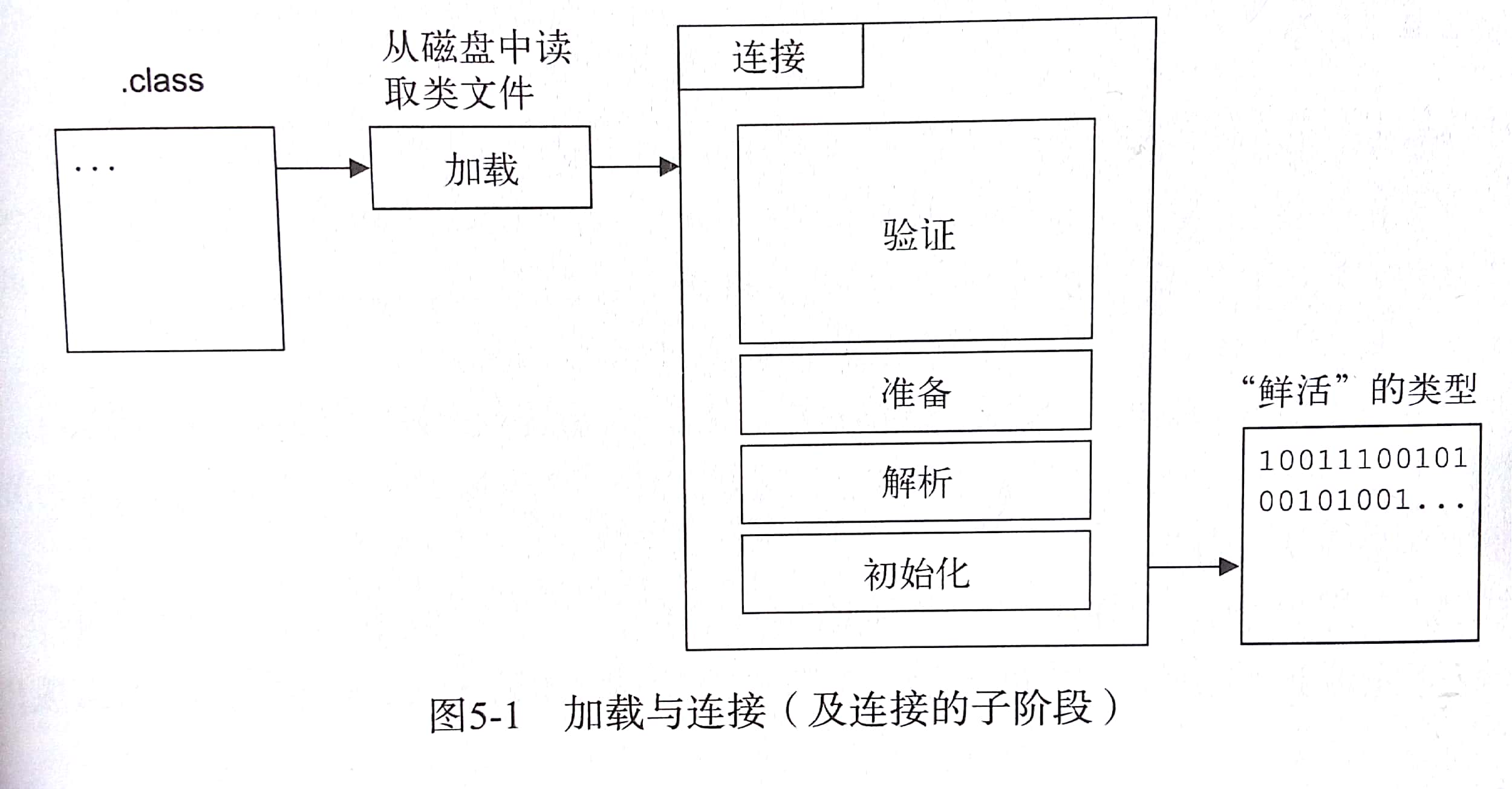
- 这个过程就是读取字节码文件,创建一个字节数组装在这些内容,加载结束后这个对象还不能直接调用
连接
- 加载完成后,类必须连接起来,分为三步:验证,准备,解析。
- 验证:
- 验证文件的合理性,完整性检查,检查常量池,方法的字节码检查。主要的:
- 是否所有方法都遵守访问控制关键字的限定
- 方法调用的参数个数和静态类型是否正确
- 确保字节码不会试图滥用堆栈
- 确保变量使用之前被正确初始化了
- 检查变量是否仅被赋予恰当类型的值
- 准备:
- 分配内存,准备初始化类中的静态变量,但不会现在就初始化,也不会执行任何VM字节码
- 解析:
- 促使VM检查类文件中所引用的类型是不是都是已知的类型。如果有运行时有未知的类型,那又要引发一次类加载过程
- 当需要加载的类全部加载解析完毕后,VM就可以初始化最初那个加载的类了。
- 这时所有的静态变量都可以进行初始化,所有静态代码块都会运行,这一步完成后,类就能使用了
- 验证:
Class对象
- 加载和连接过程的最终结果是一个Class对象,Class对象可以和反射API一起实现对方法,域构造方法等类成员的间接访问
所以一个类的定义就会有一个Class对象, 但是这个对象的类型呢?怎么判断, Class对象的类型就是他的值么?
类加载器
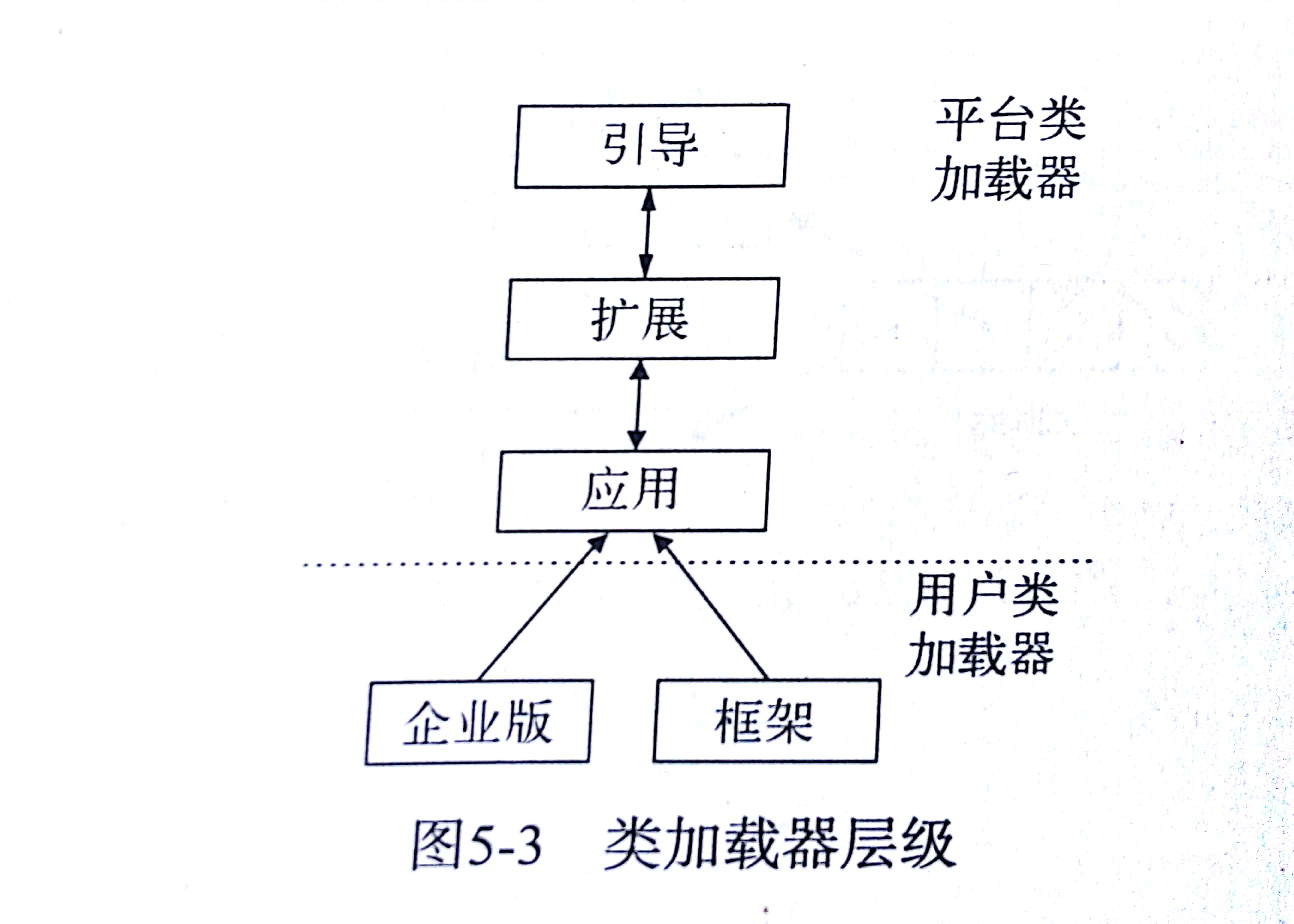
- Java平台经典类加载器:
- 根(引导)加载器: 通常在VM启动后不久就实例化,作用是加载系统的基础JAR(主要是rt.jar),并且不做验证工作
- 扩展类加载器: 加载安装时自带的标准扩展,一般包括安全性扩展
- 应用或系统类加载器: 应用最广泛的类加载器,负责加载应用类,在大多SE环境中主要工作是由他完成
- 定制类载器: 为了企业框架定制的加载器
方法句柄
主要用于反射 用到再学

检查类文件
javap
JDK内置命令, 用来探视类文件内部和反编译class文件
常量池
常量池是为类文件中的其他常量元素提供快捷访问方式的区域。对于JVM来说常量池相当于符号表 参考博客
javap -v class文件输出很多额外信息,# 开头的就是常量池信息
字节码
-
字节码是程序的中间表达形式,源码和机器码之间的产物
-
字节码是由源文件执行javac产生的
-
某些高级语言特性(语法糖)在字节码中给去掉了,例如循环结构,会转换成为分支指令
-
每个操作都由一个字节表示,因此叫做字节码
-
字节码是一种抽象表示方法
-
字节码进一步编译得到机器码
-
javap -c -p class文件反编译字节码文件,-p 能看到私有属性- 输出所有的属性以及类的定义信息
- 静态块
- 构造方法
- 方法信息
- 静态属性信息
- 静态方法信息
运行时环境
因为JVM没有CPU那样的寄存器,所以是采用的堆栈来计算的,称为操作数栈或者计算堆栈
- 当一个类被链接进运行时环境时,字节码会受到检查,其中很多验证都可以归结为对栈中类型模式的分析
- 方法需要一块内存区域作为计算堆栈来计算新值,另外每个运行的线程都需要一个调用堆栈来记录当前正在执行的方法,这两个栈会有交互
操作码介绍
- 字节码由操作码 opcode 序列构成,每个指令后可能会带参数,操作码希望看到栈处于指定状态中,然后他对栈进行操作处理,把参数移走,放入结果
- 操作码表有四列:
- 名称:操作码类型的通用名称
- 参数:操作码的参数,以i开头的是用来作为常量池或局部变量中的查询索引的几个字节,如果有更多的参数,将会合并
- 如果参数出现在括号里,就表明不是所有形式的操作码都会使用他
- 堆栈布局:他展示了栈在操作码执行前后的状态。括号中的元素表示是可选的
- 描述:描述操作码的用处
[ ] 下面的内容需要继续阅读Java7程序员修炼之道
加载和存储操作码
数学运算操作码
执行控制操作码
调用操作码
平台操作码
操作码的快捷形式
invokedynamic
这个特性是针对 框架开发和非Java语言准备的
序列化
码农翻身:序列化: 一个老家伙的咸鱼翻身
对象转化为二进制流
serialVersionUID
简单的说就是类的版本控制, 标明类序列化时的版本, 版本一致表明这两个类定义一致
在进行反序列化时, JVM会把传来的字节流中的serialVersionUID与本地相应实体(类)的serialVersionUID进行比较,如果相同就认为是一致的,可以进行反序列化,否则就会出现序列化版本不一致的异常。(InvalidCastException)
参考博客
- serialVersionUID有两种显示的生成方式:
- 一个是默认的1L
- 一个是根据类名、接口名、成员方法及属性等来生成一个64位的哈希字段
当你一个类实现了Serializable接口,如果没有定义serialVersionUID,Eclipse会提供这个提示功能告诉你去定义 。 在Eclipse中点击类中warning的图标一下,Eclipse就会自动给定两种生成的方式。 如果不想定义它,在Eclipse的设置中也可以把它关掉的,设置如下: Window ==> Preferences ==> Java ==> Compiler ==> Error/Warnings ==>Potential programming problems 将Serializable class without serialVersionUID的warning改成ignore即可。
其他业内主流编解码框架
因为Java序列化的性能和存储开销都表现不好,而且不能跨语言, 所以一般不使用Java的序列化而是使用以下流行的库
MessagePack
Protobuf
Google开源的库 全称
Google Protocol Buffers| Github : Protobuf
参考博客: Protobuf语言指南
较为详细, 只是版本有点旧参考博客: 详解如何在NodeJS中使用Google的Protobuf | protocobuf Google 开源技术protobuf Google Protocol Buffer 的使用和原理
- 他将数据结构以 proto后缀的文件进行描述, 通过代码生成工具, 可以生成对应数据结构的POJO对象和Protobuf相关的方法和属性
- 习惯性规则:
- 命名:
packageName.MessageName.proto
- 命名:
只是编解码的工具, 不支持读半包, 粘包拆包
proto文件定义
// 用户数据信息
message Article {
required int32 articleId = 1; // 文章id
optinal string articleExcerpt = 4; // 文章摘要
repeated string articlePicture = 5; // 文章附图
}
上面定义了一个消息, 消息具有三个属性, 且行末的注释都会变成Javadoc注释
- message 是消息定义的关键字
- required 表示这个字段是必需的, 必须在序列化的时候被赋值。
- optional 代表这个字段是可选的,可以为0个或1个但不能大于1个。
- repeated 则代表此字段可以被重复任意多次包括0次。
- int32和string是字段的类型。后面是我们定义的字段名。
- 最后的1,2,3则是代表每个字段的一个唯一的编号标签,在同一个消息里不可以重复。这些编号标签用与在消息二进制格式中标识你的字段,并且消息一旦定义就不能更改。
- 需要说明的是标签在1到15范围的采用一个字节进行编码。所以通常将标签1到15用于频繁发生的消息字段。编号标签大小的范围是1 到 2的29次幂–1。
- 此外不能使用protobuf系统预留的编号标签(19000 -19999)。
复杂类型
定义了enum枚举类型,嵌套的消息。甚至对原有的消息进行了扩展,也可以对字段设置默认值。添加注释等
package "com.github.kuangcp";
message Article {
required int32 article_id = 1;
optional string article_excerpt = 2;
repeated string article_picture = 3;
optional int32 article_pagecount = 4 [default = 0];
enum ArticleType {
NOVEL = 0;
PROSE = 1;
PAPER = 2;
POETRY = 3;
}
optional ArticleType article_type = 5 [default = NOVEL];
message Author {
required string name = 1; //作者的名字
optional string phone = 2;
}
optional Author author = 6;
repeated int32 article_numberofwords = 7 [packed=true];
reserved 9, 10, 12 to 15;
extensions 100 to 1000;
}
extend Article {
optional int32 followers_count = 101;
optional int32 likes_count= 102;
}
message Other {
optional string other_info = 1;
oneof test_oneof {
string code1 = 2;
string code2 = 3;
}
}
此外reserved关键字主要用于保留相关编号标签,主要是防止在更新proto文件删除了某些字段,而未来的使用者定义新的字段时重新使用了该编号标签。这会引起一些问题在获取老版本的消息时,譬如数据冲突,隐藏的一些bug等。所以一定要用reserved标记这些编号标签以保证不会被使用
当我们需要对消息进行扩展的时候,我们可以用extensions关键字来定义一些编号标签供第三方扩展。这样的好处是不需要修改原来的消息格式。就像上面proto文件,我们用extend关键字来扩展。只要扩展的字段编号标签在extensions定义的范围里。
对于基本数值类型,由于历史原因,不能被protobuf更有效的encode。所以在新的代码中使用packed=true可以更加有效率的encode。注意packed只能用于repeated 数值类型的字段。不能用于string类型的字段。
在消息Other中我们看到定义了一个oneof关键字。这个关键字作用比较有意思。当你设置了oneof里某个成员值时,它会自动清除掉oneof里的其他成员,也就是说同一时刻oneof里只有一个成员有效。这常用于你有许多optional字段时但同一时刻只能使用其中一个,就可以用oneof来加强这种效果。但需要注意的是oneof里的字段不能用required,optional,repeted关键字
导入另一个proto定义
import "article.proto";
- 更新Protobuf文件的要求:
- 不能改变已有的任何编号标签。
- 只能添加optional和repeated的字段。这样旧代码能够解析新的消息,只是那些新添加的字段会被忽略。但是序列化的时候还是会包含哪些新字段。而新代码无论是旧消息还是新消息都可以解析。
- 非required的字段可以被删除,但是编号标签不可以再次被使用,应该把它标记到reserved中去
- 非required可以被转换为扩展字段,只要字段类型和编号标签保持一致
- 相互兼容的类型,可以从一个类型修改为另一个类型,譬如int32的字段可以修改为int64
- 使用上, 因为有多个消息类型, 那么会采用一个数值id作为code, 进行对应 方便沟通
Linux上安装
只是安装2.5版本 参考博客: linux下Google的Protobuf安装及使用笔记 | 参考:proto buffer 安装 及 调用
- 下载2.5 并解压
- 进入目录
./configure make然后make check然后sudo make installprotoc --version有版本则安装成功
- 进入目录
注意: ./configure 时, 默认会安装在/usr/local目录下,可以加
--prefix=/usr来指定安装到/usr/lib下如果不加, 上述参数就要执行
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/lib
当然,可以将这个环境变量的设置加在 .zshrc 或者 .bashrc 里
不然就会报错:protoc: error while loading shared libraries: libprotobuf.so.8: cannot open shared object file: No such file or directory
通过Docker使用
对于Java的使用
Google Protocol Buffer 的使用和原理
C++ 但是原理差不多
生成Java文件
touch hi.proto
package lm;
message helloworld{
required int32 id = 1;//ID
required string str = 2;//str
optional int32 opt = 3;//optional field
}
- 据此生成Java文件
mkdir src && protoc --java_out=./src hi.proto也可以使用该脚本更新协议
# proto文件中明确定义了一样的包结构就可以直接跑脚本
basePath='minigame/proto/proto'
targetPath='ssss'
rm -rf $targetPath \
&& mkdir $targetPath \
&& protoc $basePath/*.proto --java_out=$targetPath \
使用
// 实例化一个构建器
helloworld.Builder msg = helloworld.newBuilder();
// 填充信息
msg.setId(12);
Thrift
源于Facebook, 支持多种语言: C++ C# Cocoa Erlang Haskell Java Ocami Perl PHP Python Ruby Smalltalk
- 它支持数据(对象)序列化和多种类型的RPC服务, Thrift适用于静态的数据交换, 需要预先确定好他的数据结构, 当数据结构发生变化时,需要重新编辑IDL文件
Marshalling
JBOSS 内部使用的编解码框架