栈,队列,链表
先来看一下数组 数组是一种连续存储线性结构,元素类型相同,大小相等
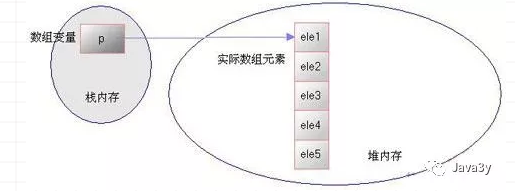
数组的优缺点:
- 因为可以随意访问所以查询速度快
- 因为往中间插入或删除数据,会新建数据来进行,所以比较慢
- 空间通常是有限制的
- 需要大块连续的内存块
栈和队列都是基于数组的数据结构
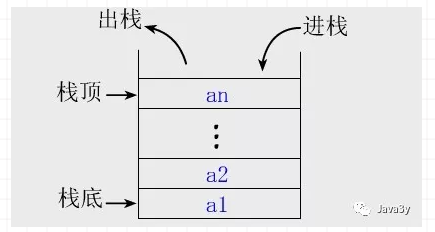
栈
后进先出
可以把栈看成一个桶,往里边放苹果,底部的苹果想要拿出来,得先把顶部的苹果取走才行
/**
* 栈的实现
* @param <T>
*/
public class Stack_demo<T> {
ArrayList<T> stack = new ArrayList<T>();
private int top = -1;
/**
* 入栈
* @param item
*/
public void push(T item){
stack.add(item);
top++;
}
/**
* 出栈
* @return T
*/
public T pop(){
List<String> list = new ArrayList<>();
T tmp = stack.get(stack.size()-1);
stack.remove(stack.size()-1);
top--;
return tmp;
}
/**
* 判断是否为空
* @return boolean
*/
public Boolean stackempty(){
if(top == -1){
return true;
}
else{
return false;
}
}
}
队列
队列就是这个样子
先进先出
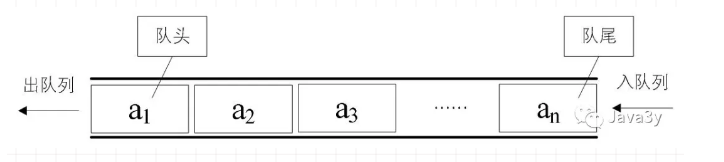
其实队列非常好理解,我们将队列可以看成小朋友排队,先排队的小朋友肯定能先打到饭!
关于队列的实现可参考: java数据结构与算法之(Queue)队列设计与实现
链表
链表是离散存储线性结构
n个节点离散分配,彼此通过指针相连,每个节点只有一个前驱节点,每个节点只有一个后续节点,首节点没有前驱节点,尾节点没有后续节点,每个节点都存储着数据和指向另一个节点的指针
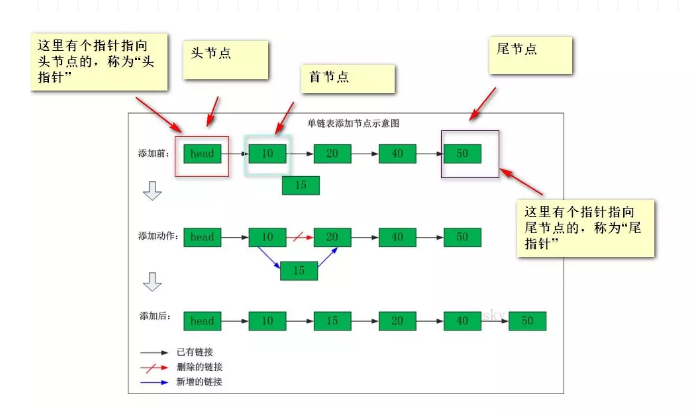
链表的优缺点:
- 空间没有限制
- 插入删除元素很快
- 由于需要从头结点开始推导,所以查询速度比较慢
开始分析链表的实现,这里先从单链表入手。同样地,先来定义一个顶级的链表接口:ILinkedList和存储数据的结点类Node
//单项链表节点类
public class Node<T> {
public T data;//数据域
public Node<T> next;//地址域
public Node(T data){
this.data=data;
}
public Node(T data,Node<T> next){
this.data=data;
this.next=next;
}
}
// 链表接口
public interface ILinkedList<T> {
/**
* 判断链表是否为空
* @return
*/
boolean isEmpty();
/**
* 链表长度
* @return
*/
int length();
/**
* 获取元素
* @param index
* @return
*/
T get(int index);
/**
* 设置某个结点的的值
* @param index
* @param data
* @return
*/
T set(int index, T data);
/**
* 根据index添加结点
* @param index
* @param data
* @return
*/
boolean add(int index, T data);
/**
* 添加结点
* @param data
* @return
*/
boolean add(T data);
/**
* 根据index移除结点
* @param index
* @return
*/
T remove(int index);
/**
* 根据data移除结点
* @param data
* @return
*/
boolean removeAll(T data);
/**
* 清空链表
*/
void clear();
/**
* 是否包含data结点
* @param data
* @return
*/
boolean contains(T data);
/**
* 输出格式
* @return
*/
String toString();
}
// 单链表SingleILinkedList并实现ILinkedList接口
public class SingleILinkedList<T> implements ILinkedList<T> {
protected Node<T> headNode; //带数据头结点
public SingleILinkedList(Node<T> head) {
this.headNode = head;
}
//判断链表是否为空,只需判断头结点是否为空
@Override
public boolean isEmpty() {
return this.head==null;
}
//获取链表长度,从头结点开始遍历
@Override
public int length() {
int length=0;//标记长度的变量
Node<T> p=head;//变量p指向头结点
while (p!=null){
length++;
p=p.next;//后继结点赋值给p,继续访问
}
return length;
}
//get(index)方法,效率低,从头开始查找
@Override
public T get(int index) {
if(this.head!=null&&index>=0){
int count=0;
Node<T> p=this.head;
//找到对应索引的结点
while (p!=null&&count<index){
p=p.next;
count++;
}
if(p!=null){
return p.data;
}
}
return null;
}
//set(index,data)方法,和get原理差不多
@Override
public T set(int index, T data) {
if(this.head!=null&&index>=0&&data!=null){
Node<T> pre=this.head;
int count=0;
//查找需要替换的结点
while (pre!=null&&count<index){
pre=pre.next;
count++;
}
//不为空直接替换
if (pre!=null){
T oldData=pre.data;
pre.data=data;//设置新值
return oldData;
}
}
return null;
}
//add
/**
* 根据下标添加结点
* 1.头部插入
* 2.中间插入
* 3.末尾插入
* @param index 下标值从0开始
* @param data
* @return
*/
@Override
public boolean add(int index, T data) {
if (data==null){
return false;
}
//在头部插入
if (this.head==null||index<=1){
this.head = new Node<T>(data, this.head);
}else {
//在尾部或中间插入
int count=0;
Node<T> front=this.head;
//找到要插入结点位置的前一个结点
while (front.next!=null&&count<index-1){
front=front.next;
count++;
}
//尾部添加和中间插入属于同种情况,毕竟当front为尾部结点时front.next=null
front.next=new Node<T>(data,front.next);
}
return true;
}
//remove
@Override
public T remove(int index) {
T old=null;
if (this.head!=null&&index>=0){
//直接删除的是头结点
if(index==0){
old=this.head.data;
this.head=this.head.next;
}else {
Node<T> front = this.head;
int count = 0;
//查找需要删除结点的前一个结点
while (front.next != null && count < index - 1) {
front = front.next;
count++;
}
if ( front.next!= null) {
//获取旧值
old =front.next.data;
//更改指针指向
front.next=front.next.next;
}
}
}
return old;
}
//clear
@Override
public void clear() {
this.head=null;
}
}
书籍推荐