map
- map集合存储的是键值对,不能包含重复的键,必须保证键的唯一性。
- map集合的key是无序的
常用方法
增改
value put(k,v);返回key前一个对应的值
删
void clear value remove(key)
查
boolean containsKey(k)
boolean containsValue(v)
boolean isEmpty()
value get(key) 如果没有该key,则返回null,可以判断是否包含指定key
int size()
Map<Integer,String> map = new HashMap<Integer, String>();
//增加修改
System.out.println(map.put(1, "wangcai")); //null
System.out.println(map.put(1, "xiaoqiang")); //wangcai 集合中的键不能重复,重复就覆盖
System.out.println(map); //{1=xiaoqiang}
map.put(2, "zhgangshan");
map.put(3, "lisi");
//删除
System.out.println("remove:.."+map.remove(2)); //remove:..zhgangshan
System.out.println(map); //{1=xiaoqiang, 3=lisi}
//判断
System.out.println("containsKey:.."+map.containsKey(2)); //containsKey:..false
System.out.println("containsvalue:.."+map.containsValue("zhgangshan"));
//获取
System.out.println(map.get(3)); //lisi
遍历
- Set keySet 原理:通过keyset方法获取map中所有键所在的Set集合,再通过Set迭代器获取到每一个键,再取值
Set<Integer> keys = map.keySet();
Iterator<Integer> it = keys.iterator();
while(it.hasNext()) {
Integer key = it.next();
String value = map.get(key);
System.out.println(key+":"+value);
}
- Set entrySet 将键值对的映射关系存储到Set集合中,这就是键值对的结婚证 Entry是Map的内部接口
Set<Map.Entry<Integer,String>> entry = map.entrySet();
Iterator<Map.Entry<Integer,String>> it = entry.iterator();
while(it.hasNext()) {
Map.Entry<Integer,String> me = it.next();
Integer key = me.getKey();
String value = me.getValue();
System.out.println(key+":"+value);
}
- Collection values 获取值的集合
Collection<String> values = map.values();
Iterator<String> it = values.iterator();
while(it.hasNext()) {
System.out.println(it.next());
}
子类
- HashTable:内部结构哈希表,同步,不允许null作为键值
- Properties:存储键值对的配置文件信息
- HashMap:内部结构哈希表,不同步,允许null作为键值
- TreeMap:内部结构是二叉树,不同步,可以对键进行排序 Set底层就是Map
HashMap
底层还是哈希表,所以判断键的重复,hashcode equals
HashMap<Student,String> hs = new HashMap<Student,String>();
hs.put(new Student("s1",21), "上海");
hs.put(new Student("s2",22), "北京");
hs.put(new Student("s3",23), "成都");
hs.put(new Student("s4",24), "广州");
hs.put(new Student("s1",21), "杭州"); //自动调用Person的equals,hashCode方法,覆盖
Iterator<Student> it = hs.keySet().iterator();
while(it.hasNext()) {
Student key = it.next();
String value = hs.get(key);
System.out.println(key.getName()+":"+key.getAge()+"---"+value);
}
HashMap的底层实现

TreeMap
key 唯一 升序 红黑树 如果使用TreeMap存储自定义类,必须具备比较器,否则报错
自定义类实现Comparable
TreeMap<Person,String> hs = new TreeMap<Person,String>();
hs.put(new Person("s1",21), "上海");
hs.put(new Person("s2",26), "北京");
hs.put(new Person("s3",23), "成都");
hs.put(new Person("s4",24), "广州");
hs.put(new Person("s1",21), "杭州");
//自动调用Person的equals,hashCode方法
Iterator<Map.Entry<Person,String>> it = hs.entrySet().iterator();
while(it.hasNext())
{
Map.Entry<Person,String> me = it.next();
Person key =me.getKey();
String value = me.getValue();
System.out.println(key.getName()+":"+key.getAge()+"---"+value);
}
/*
s1:21---杭州
s3:23---成都
s4:24---广州
s2:26---北京
*/
public class Person extends Object implements Comparable<Person> {
private String name;
private int age;
public Person(String name, int age) {
super();
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public int compareTo(Person p) {
int temp = this.age-p.age;
return temp;
}
}
使用外部比较器
TreeMap<Student,String> hs = new TreeMap<Student,String>(new ComparatorByName());
hs.put(new Student("s1",21), "上海");
hs.put(new Student("s2",26), "北京");
hs.put(new Student("s3",23), "成都");
hs.put(new Student("s4",24), "广州");
hs.put(new Student("s1",21), "杭州"); //自动调用Person的equals,hashCode方法
Iterator<Map.Entry<Student,String>> it = hs.entrySet().iterator();
while(it.hasNext()) {
Map.Entry<Student,String> me = it.next();
Student key = me.getKey();
String value = me.getValue();
System.out.println(key.getName()+":"+key.getAge()+"---"+value);
}
public class ComparatorByName implements Comparator<Person> {
@Override
public int compare(Person p1, Person p2) {
// Person p1 = (Person)o1;
// Person p2 = (Person)o2;
int temp = p1.getName().compareTo(p2.getName());
return temp==0?p1.getAge()-p2.getAge() : temp;
}
}
TreeMap源码分析
public class TestTreeMap {
/***
* TreeMap的底层实现
*
* private final Comparator<? super K> comparator; 外部比较器,用于比较大小的
* private transient Entry<K,V> root; //代表的是树根
* public TreeMap() {
comparator = null;
}
public V put(K key, V value) {
Entry<K,V> t = root; //指向树根
if (t == null) {
//比较大小
compare(key, key); // type (and possibly null) check
//创建一个根节点
root = new Entry<>(key, value, null);
size = 1; //个数++
modCount++;
return null;
}
int cmp;
Entry<K,V> parent; //父节点
// split comparator and comparable paths
*
Comparator<? super K> cpr = comparator; //null
//如果外部比较器不等于null,说明外部比较器存在
if (cpr != null) {
do {
parent = t; //把root赋给父节点
cmp = cpr.compare(key, t.key); //调用外部比较器的比较方法开始比大小,结果是一个int类型的值
if (cmp < 0)
t = t.left; //在左子树上查找
else if (cmp > 0) //在右子树上查找
t = t.right;
else
return t.setValue(value); //找到了,值进行覆盖
} while (t != null);
}
else { //外部比较器不存在,使用内部比较器进行比较
if (key == null)
throw new NullPointerException();
@SuppressWarnings("unchecked")
Comparable<? super K> k = (Comparable<? super K>) key;
do {
parent = t; //root赋给父节点
cmp = k.compareTo(t.key); //调用内部比较器的比较大小的方法,比较结果为int类型
if (cmp < 0)
t = t.left; //在左子树上查找
else if (cmp > 0) //在右子树上查找
t = t.right;
else
return t.setValue(value); 找到了值的覆盖
} while (t != null);
}
//创建一个节点
Entry<K,V> e = new Entry<>(key, value, parent);
if (cmp < 0)
parent.left = e; //添加到左子树
else
parent.right = e; //添加到右子树
fixAfterInsertion(e);
size++;
modCount++;
return null;
}
*/
public static void main(String[] args) {
//创建集合对象
//TreeMap treeMap=new TreeMap();
//创建外部比较器对象,定义比较规则
Comparator comLength=new CompareLength();
TreeMap treeMap=new TreeMap(comLength);
//添加数据
treeMap.put("hello", 123);
treeMap.put("world1", 456);
treeMap.put("hello11", 789);
treeMap.put("java", 1000);
System.out.println("集合中元素的个数:"+treeMap.size());
System.out.println(treeMap);
System.out.println(treeMap.containsKey("hello")+"\t"+treeMap.containsKey("sql"));
System.out.println(treeMap.containsValue(789)+"\t"+treeMap.containsValue(1002));
System.out.println(treeMap.get("java"));
}
}
LinkedHaspMap
HashMap<Integer,String> hs = new LinkedHashMap<Integer,String>(); //保证存入和取出顺序一致
hs.put(7, "zhangsan1");
hs.put(8, "zhangsan2");
hs.put(2, "zhangsan3");
Iterator<Map.Entry<Integer,String>> it = hs.entrySet().iterator();
while(it.hasNext()) {
Map.Entry<Integer,String> me = it.next();
Integer key = me.getKey();
String value = me.getValue();
System.out.println(key+":"+value);
}
练习

String str = "f+_dgavcbsacADdfs";
char[] chs = str.toCharArray();
Map<Character,Integer> map = new TreeMap<>();
for(int i=0;i<chs.length;i++) {
if(chs[i]>='a' && chs[i]<='z' || chs[i]>='A' && chs[i]<='Z') {
Integer value = map.get(chs[i]);
if(value==null) {
map.put(chs[i], 1);
}else {
map.put(chs[i], value+1);
}
}
}
StringBuilder sb = new StringBuilder();
Iterator<Character> it = map.keySet().iterator();
while(it.hasNext()) {
Character key = it.next();
Integer value = map.get(key);
sb.append(key+"("+value+")");
}
System.out.println(sb.toString());
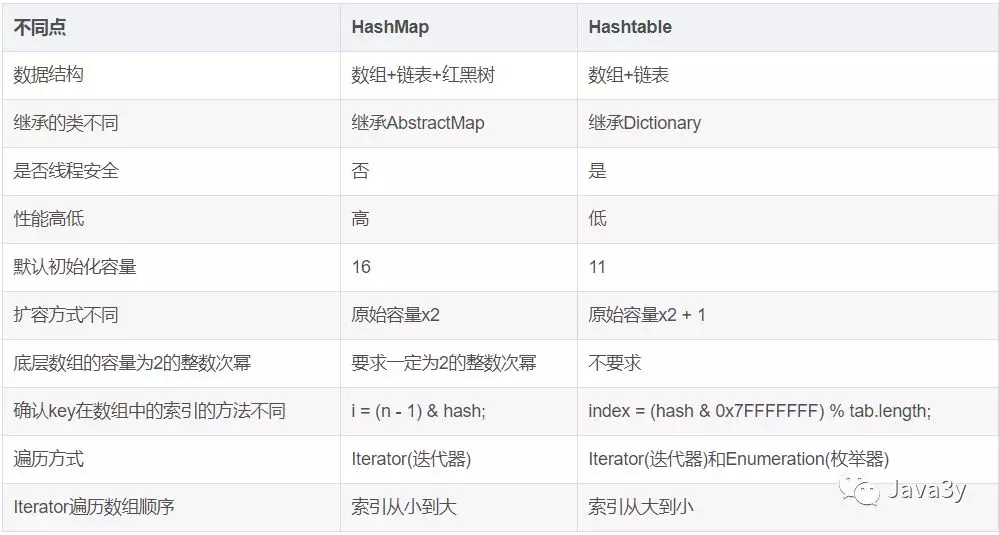
HashMap与Hashtable对比
总结
在JDK8中HashMap的底层是:数组+链表(散列表)+红黑树
在散列表中有装载因子这么一个属性,当装载因子*初始容量小于散列表元素时,该散列表会再散列,扩容2倍!
装载因子的默认值是0.75,无论是初始大了还是初始小了对我们HashMap的性能都不好
装载因子初始值大了,可以减少散列表再散列(扩容的次数),但同时会导致散列冲突的可能性变大(散列冲突也是耗性能的一个操作,要得操作链表(红黑树)!
装载因子初始值小了,可以减小散列冲突的可能性,但同时扩容的次数可能就会变多!
初始容量的默认值是16,它也一样,无论初始大了还是小了,对我们的HashMap都是有影响的:
初始容量过大,那么遍历时我们的速度就会受影响~
初始容量过小,散列表再散列(扩容的次数)可能就变得多,扩容也是一件非常耗费性能的一件事~
从源码上我们可以发现:HashMap并不是直接拿key的哈希值来用的,它会将key的哈希值的高16位进行异或操作,使得我们将元素放入哈希表的时候增加了一定的随机性。
还要值得注意的是:并不是桶子上有8位元素的时候它就能变成红黑树,它得同时满足我们的散列表容量大于64才行的~
书籍推荐